Since the release of the Racket
Manifesto by
Felleisen, et al. it has become a thesis of mine that normal
programmers face, on a regular basis, real problems which could be
alleviated by the sorts of macro mechanisms offered by Racket (and to
a lesser extent, other Lisps). I’ve got in mind some in-depth
investigations I’d like to perform to really back this argument up,
but until I have time for that, a recent article will serve as a
sort of teaser for what I’ve got in mind.
When writing program code, programmers often have to write a series
of similar constructs. Typing the same code several times is boring
and inefficient. That’s why they use the Copy-Paste method: a code
fragment is copied and pasted several times with further
editing. Everyone knows what is bad about this method: you risk
easily forgetting to change something in the pasted lines and thus
giving birth to errors. Unfortunately, there is often no better
alternative to be found.
Now let’s speak of the pattern I discovered. I figured out that
mistakes are most often made in the last pasted block of code.
Andrey goes on to provide some evidence for his assertion. I think
he’s on to something, and it makes sense. You do your pasting, then
you set your hands in motion with some repeated delete delete delete
type type type down arrow, repeat. By the time you’ve done that three
or four times, your mind is numb, your eyes are glazed, and the
muscles aren’t being supervised anymore.
I’d like to point out and discuss two of his examples:
They’ve got some bitmasks that are referenced via variables (they’re
probably #defines, but it doesn’t matter), and when the relevant
bits are set, they’d like to write out the name of the bitmask that
was set. Turns out this could actually be implemented as a function:
Hmm. Not really an improvement. We’re still duplicating things. And
the repetition of access and output is tedious. I’d expect most
programmers to copy and paste the function call. Back where we started.
The C macro system happens to be powerful enough to address this case:
#define C_A(a,o,s) \
if (a & s) \
o.append(ASCIIToUTF16("\t" #s "\n"));
C_A(access,output,FILE_WRITE_ATTRIBUTES)
will expand to what we want.
This accomplishes our goal, because the macro is able to see the symbol
FILE_WRITE_ATTRIBUTES, rather than just the value of 0x00100 or whatever
it might happen to be.
We could shorten the uses of C_A by having the macro definition
refer directly to access and output. But sooner or later, that
will trip over standard macro
hygiene problems.
And, unsurprisingly, that doesn’t work. Perhaps a more clever C
preprocessor could notice that the for loop is static, and generate
all of the appropriate code. Maybe there’s even some option I don’t
remember floating around that would work with existing preprocessors.
Frankly, I’m pleased I remember how to do the stringification and
concatenation.
That’s not short. But if you’re going to be writing a lot of code
where you want to pull values out of variables with numbers in their
names, and stuff those values into corresponding positions in arrays,
wouldn’t it be nice to have? How many times would you need to use it
before it became worth the effort, in order to avoid the copying and
pasting?
How much effort would it be worth to eliminate a class of errors?
Finally
Refer back to the bold portion of Andrey’s text: “there is often
no better alternative to be found”. What? We’re programming! We’re
providing instructions to a machine, which will be faithfully executed
on our behalf, regardless of how tedious and repetitive they may be,
and there’s no better alternative than copying and pasting?
When the Racket manifesto discusses Racket’s design principles, the
authors write:
When programmers must resort to extra-linguistic mechanisms to solve
a problem, the chosen language has failed them.
I assert that copying and pasting code is an extra-linguistic
mechanism for expressing repetition the language is incapable of. When
you are left with no choice but to copy and paste code, your language
has failed you.
I thought it might help if people could play with the LMSR directly,
to get a feel for how it behaves. I looked around at my options for
making interactive mathematical plots, and decided that the best option
for the amount of time I was willing to put in was Mathematica CDF
files. You’ll need the
CDF player installed.
You should have two sliders, “start” and “tradeto”, as well as a graph
with two curves on it, one red, the other green. If not, something has
gone awry. Sorry.
The value of “start” represents where the trade is starting from; the
current state of the market. “tradeto” is the value of the trade you’re
considering making (this assumes power mode). “start” and “tradeto” are
depicted visually on the graph by vertical lines labelled “S” and “T”.
“start” controls a second line, labelled ▽.
Where T intersects with the Yes (green) and No (red) lines, there is a
number which is the points you’ll gain (positive) or lose (negative),
if the question resolves as Yes, or No, respectively. Between the S
and ▽ lines, any trade you make has the potential to earn more than it
risks. Everywhere between those lines has decimal
odds of ≥2.0.
I have a number of other interactive graphs I’m planning to put up,
but I’m still tweaking them. If you’ve got access to Mathematica, and
you’d care to root around in my scicasting
repo you can find my
more-or-less in progress Mathematica notebook where I’m developing
them.
On a programming note, these graphs are the most complicated things
I’ve ever bothered to do in Mathematica. I’m pleased to discover that
a lot of the horrifying looking Mathematica code I’ve seen on their
blog, and elsewhere on the Internet over the years, was much worse
than it had to be. Apparently nobody believes in adding whitespace to
format things nicely. On the downside, it still hurts to read.
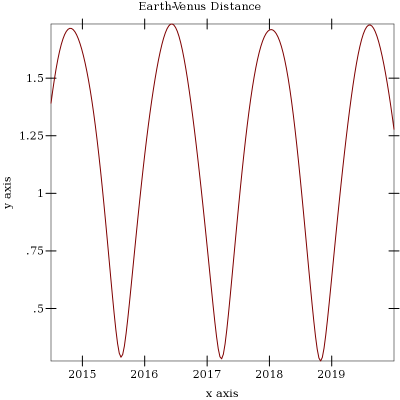
My Venus model presupposes there are three launch windows (2015, 2016
and 2018) for Venus. I also mention that in my comment on SciCast,
though I don’t mention how I determined that.
I’m going to assume you have a reasonable mental model of planets, and
their orbits around the Sun. Further, you believe that with current
propulsion techniques, there are better and worse times to launch when
you want to get to another planet.
Ok, first step, you hit up JPL’s
HORIZONS web site. Set your
Target Body to Venus (it’ll be 299; that’s the NAIF
SPICE ID for Venus), the
Time Span to run from 2014-7-1 to 2020-1-1 with a step size of 1
calendar month. Pull up the table settings and turn off everything
except #20 Observer range & range-rate. Hit Generate Ephemeris. Bam,
you’ve got a table of how far apart Venus and the Earth are, on a
monthly basis, for the chunk of time under consideration in the
question.
You could plot it, and you’d get something looking suspiciously
like this:
Hey look, three dips, almost in the three years I mention. Those
correspond to the points when the planets are closest, and are roughly
the best time to try and get from the Earth to Venus. Since Venus zips
around the Sun quite a bit faster than the Earth, every close approach
is Venus “catching up” with us.
The best plan for launching, then, is to kick it out of orbit into the
direction of Venus, and let Venus catch up to it. The transit then
just takes a few months. You can work out a good time to launch by
shaving a few months off each of the minimums on the graph. That’s why
the 2017 dip corresponds to a (late) 2016 launch window.
I’m going to assume you’re familiar with
SciCast; if you aren’t, that link is the
place to start. Or maybe Wikipedia.
There has been a open question on SciCast, “Will Bluefin-21 locate
the black box from Malaysian Airlines flight
MH-370?”, since mid-April.
(If you don’t know what MH370
is, I envy you.) It dropped fairly
quickly to
predicting that there was a 10% chance of Bluefin-21 locating MH370.
Early on, that was reasonable enough. There was evidence pings from
the black box had been detected in the region, so the entire Indian
Ocean had been narrowed down to a relatively small area.
Unfortunately weeks passed and on May 29th Bluefin-21’s mission was
completed,
unsuccessfully. Bluefin-21 then stopped looking. At this point, I (and
others) expected the forecast to plummet. But folks kept
pushing it back up. In fact I count about 5 or 6 distinct individuals
who moved the probability up after completion of the mission. There
are perfectly good reasons related to the nature of the prediction
market for some of those adjustments.
I’m interested in the bad reasons.
One of the bad reasons that could apply to any question, but seems to
be a very likely candidate for this question, is being unaware of the
state of the world. Forecasting the future when you don’t know the
present just isn’t going to turn out very well. In the best case,
you’ve got really good priors, and you’re stuck working off of
those. Realistically, your priors aren’t that great. Evidence could
help them out, but you’re not updating.
In the specific case of the Bluefin-21, it was suggested (by someone
with whom I have no beef, and am not trying to single out!) that there
was still a chance MH370 would be discovered by going back and
reanalyzing the data.
This didn’t seem at all likely to me. I attempted to explain why,
though in retrospect I think my explanation was poor, and incomplete.
To formalize my reasoning, I hunted around for a software tool that
would let me crunch the numbers and make a diagram. I turned up
GeNIe, which looked appropriate for the
task. GeNIe is a GUI on top of SMILE, which is a software library for
(handwave) modeling Bayesian
networks.
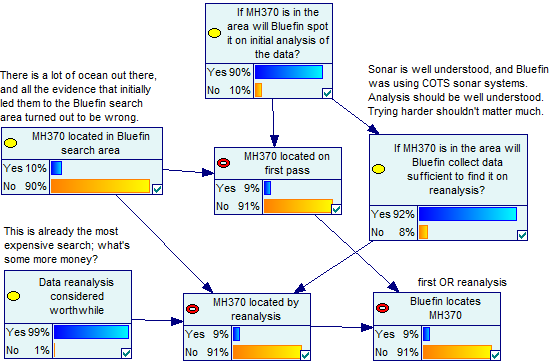
I ended up producing this model and looks like this:
(If you want to fiddle with the model, you can download it
here.)
This model assumes Bluefin-21 is 90% effective on the first pass, and
reanalysis has a 20% chance to find MH370 if it was missed. It also
assumes that reanalysis will almost certainly happen, but that there
is only a 10% chance that MH370 is even in the search area. I feel
that’s generous given the search area, and nature of the acoustic
evidence. (I never thought the surface debris was likely to be
related. There’s a lot of crap in the
ocean. That
they found so little is just evidence of the size of the ocean.)
Based on all of that, the model says there’s a 9% chance Bluefin-21 would
find MH370. Which is about where the SciCast prediction was at. The
other forecasters might’ve been giving the pings more credit. Anyways,
we’re kind of in the ballpark. So let’s now tell the model that Bluefin-21
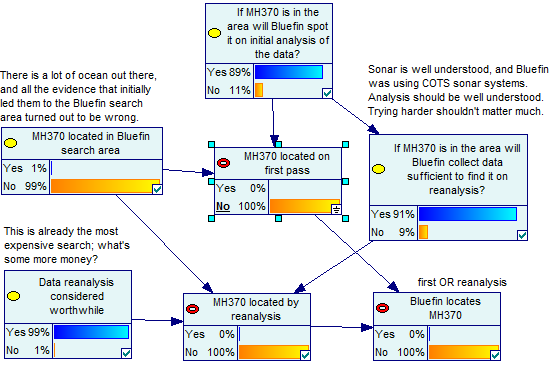
didn’t find MH370 on the first pass, and see what it says:
Weee, the chance that Bluefin-21 will find anything has now dropped to
basically zero. And that’s because not finding the MH370 on the first
pass is evidence that it isn’t there, even if Bluefin-21 is
imperfect. In fact, the better Bluefin-21 is, the stronger the
evidence of absence. For any chance of detection to remain, Bluefin-21
would have to be good at collecting data, but the analysis would have
to be awful and error prone, unless you repeated it. I didn’t attempt
to model that in, because it would be so weird.
First, sonar is well understood, and Bluefin-21 was using COTS units
that basically produce a elevation model of the ocean floor. Second,
if “trying harder” upped the odds of detection, then the operators
would throw more CPU or man power at it until they’d raised the
likelihood of detection as high as it was reasonably going to go. The
cost of the search had hit at least $44 million before Bluefin-21 got
wet; some additional data analysis isn’t going to put a dent in that.
(Maybe you could find a signal processing researcher to apply some
cutting edge stuff, but if that didn’t happen at the start of the
search, I don’t think it’ll happen before the question expires.)
This question is pretty much over, but if you have suggestions for
making the model better, I’d be interested in hearing them. This is
the first thing I’ve done with this sort of modeling tool. So I’m
sure some things could be done better.
next?
I plan to make further use of GeNIe for my SciCasting. For starters,
the models make it easier to break apart the separate components of my
belief. I can also tweak nodes and have the machine handle propagating
the change, which will be much more accurate than fuzzily doing it in
my head.
Using some of the fancier(?) features should also allow me to
focus my forecasting efforts and points on the questions where I can
get the best returns. (Basically by answering the obvious question
of “Am I sure enough to make it worth it?”)
Finally, I’d like to put my models up like this, along with some
explanation. That way I can demonstrate that I’m predicting the future
on the basis of cunning and wit, not piles of luck. ☺